

PRML - Lab 1: KNN 算法
本次作业利用 NumPy 实现了一个 KNN 模型。
Pattern Recognition and Machine Learning (H) @ Fudan University, spring 2021.
实验简介
实验报告
1 KNN 模型实现
KNN 算法(\(k\)-nearest neighbors algorithm)的主要思路是:根据当前点 \(P_0\) 最近的 \(k\) 个邻居 \(P\) 的标签,选择其中出现频率最高的标签,作为 \(P_0\) 标签的预测结果。
具体来说,我们使用函数 _distance 获取两点间的距离。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
这里我们使用了 numpy 库提供的 np.linalg.norm 方法来获取两点间的距离。特别地,当参数 ord 为 2 时,即采用 Euclidean 距离。我们这里使用 2 作为默认参数。
接下来,我们维护一个大小为 \(k\) 的最小堆,来得到最近的 \(k\) 个邻居。思想就是 top k 问题的经典算法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
最后我们对这 \(k\) 个邻居的标签分别进行计数,选择其中出现次数最多的标签作为预测结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
训练模型时,我们先将数据集打乱,然后将其中的 \(75\%\) 作为训练集 train_data,剩下 \(25\%\) 作为验证集 dev_data,然后使用 KNN 算法进行训练。我们选择不同的 \(k\) 值,通过比较验证集 dev_data 的预测结果和其实际标签 dev_label,得到每个 \(k\) 值所对应的预测准确率 accuracy。最终,我们选择准确率最高的 \(k\) 值作为测试集 test_data 上使用的参数 \(k\)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | |
对测试集进行预测时,我们就使用之前得到的最优的参数 \(k\) 进行预测,同样使用 KNN 算法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
2 生成数据
我们使用不同的参数生成数据集,并保存到文件 data.npy。这里由于时间有限,为了方便起见,我们直接在函数 generate 的 parameters 变量中进行参数的修改。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | |
为了直观起见,我们提供了函数 display 用于将当前使用的数据集可视化,并将图片保存到 img 目录下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
3 运行代码
在当前目录下,我们可以使用以下参数执行代码 source.py,具体功能参见注释。
1 2 3 4 5 | |
3.1 输出样例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | |
4 实验探究
4.1 实验 1
4.1.1 参数
1 2 3 | |
1 2 3 | |
1 2 3 | |
其中:
mean表示数据集的均值cov表示数据集的协方差size表示数据集的大小
4.1.2 数据集
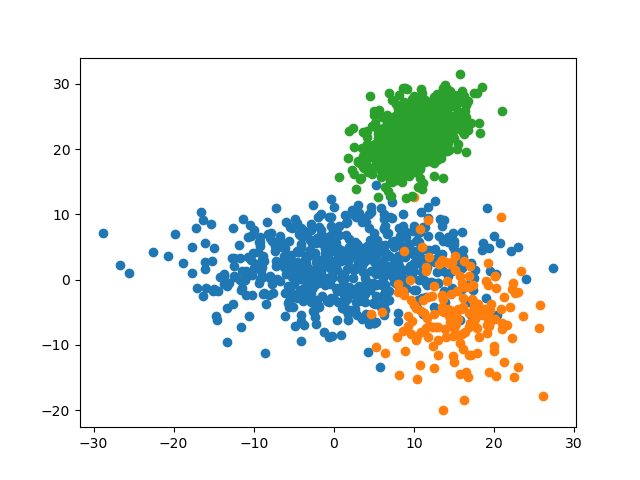
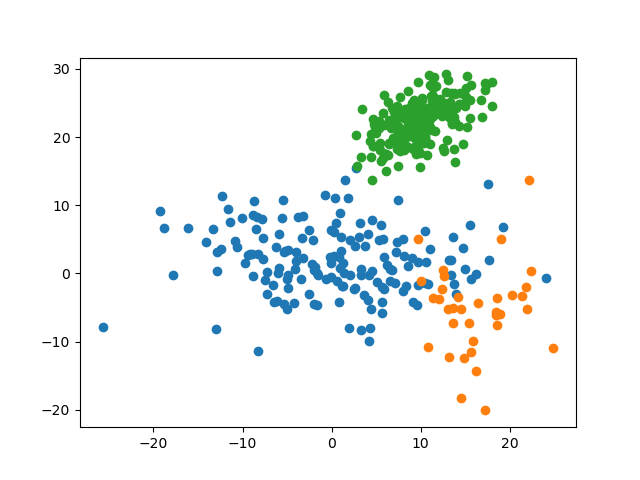
4.1.3 预测准确率
训练时使用的参数 \(k\) 及相应的准确率如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
预测时使用的参数 \(k\) 及相应的准确率如下所示:
1 | |
可见,对于此数据集,最优的参数 \(k\) 为 \(3\),其对测试集的预测准确率为 \(96.0\%\)。
4.2 实验 2
这次,我们调大数据集之间的距离,观察预测准确率的变化。
4.2.1 参数
1 2 3 | |
1 2 3 | |
1 2 3 | |
4.2.2 数据集
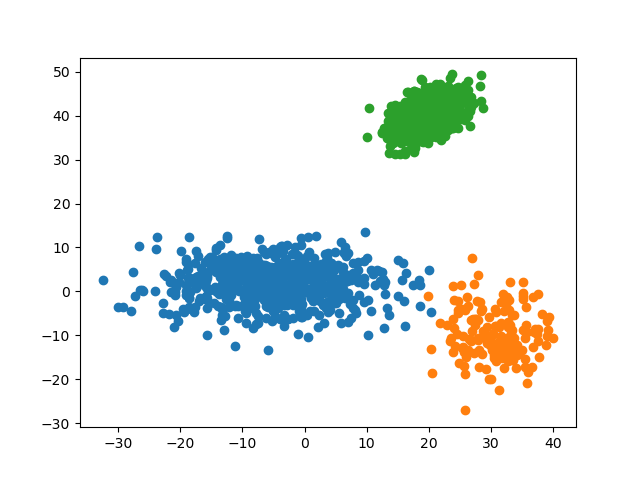
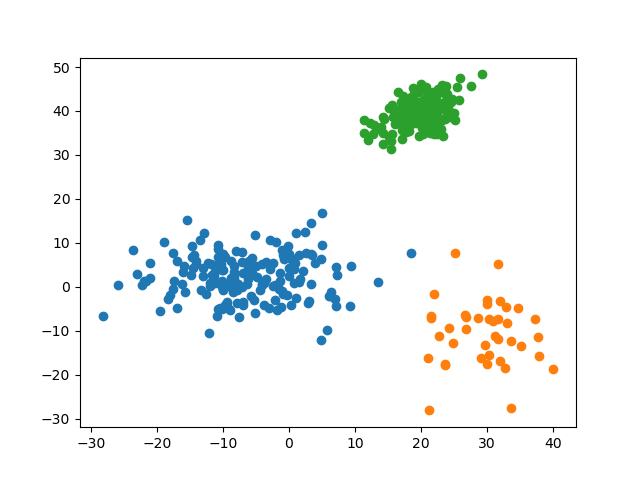
4.2.3 预测准确率
训练时使用的参数 \(k\) 及相应的准确率如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
预测时使用的参数 \(k\) 及相应的准确率如下所示:
1 | |
可见,对于不同标签区分度较大(即彼此间距离较远)的数据集,所有 \(k\) 的预测准确率均为 \(100.0\%\)。这说明 KNN 算法对于较分散的数据有着很高的准确率。
4.3 实验 3
我们再试试减小数据集间的距离,观察预测准确率的变化。
4.3.1 参数
1 2 3 | |
1 2 3 | |
1 2 3 | |
4.3.2 数据集
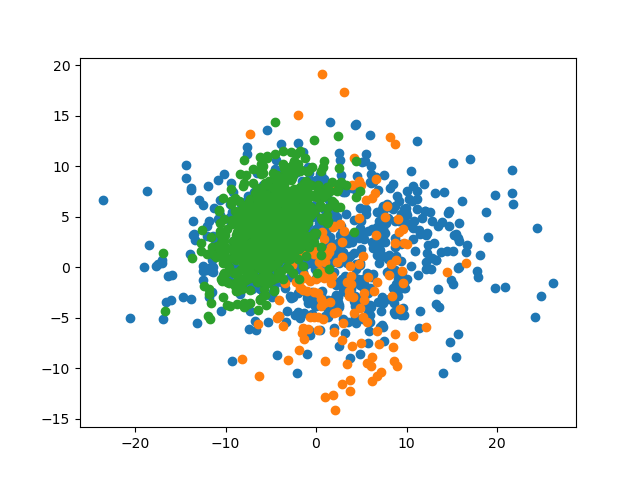
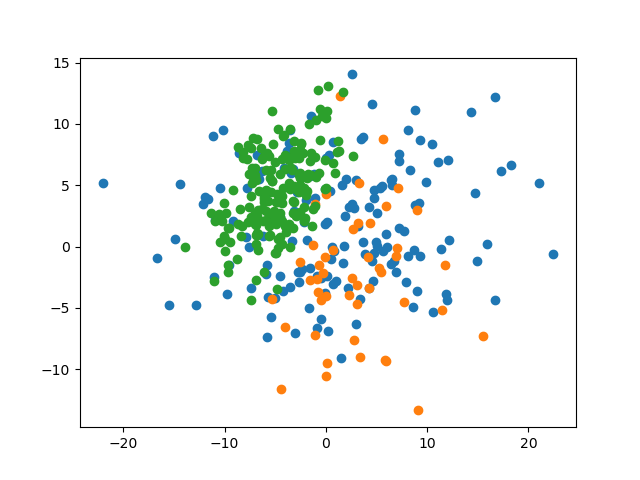
4.3.3 预测准确率
训练时使用的参数 \(k\) 及相应的准确率如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
预测时使用的参数 \(k\) 及相应的准确率如下所示:
1 | |
此时,最优的参数 \(k\) 为 \(9\),其对测试集的预测准确率为 \(76.0\%\)。可见,当数据集间的区分度较低时,较高的 \(k\) 值有着相对较高的准确率。这是可以理解的,因为提高可参考的邻居数量可以尽可能地减少噪声的影响。